¿Cómo está diseñado Google Drive? Arquitectura de un sistema de almacenamiento global
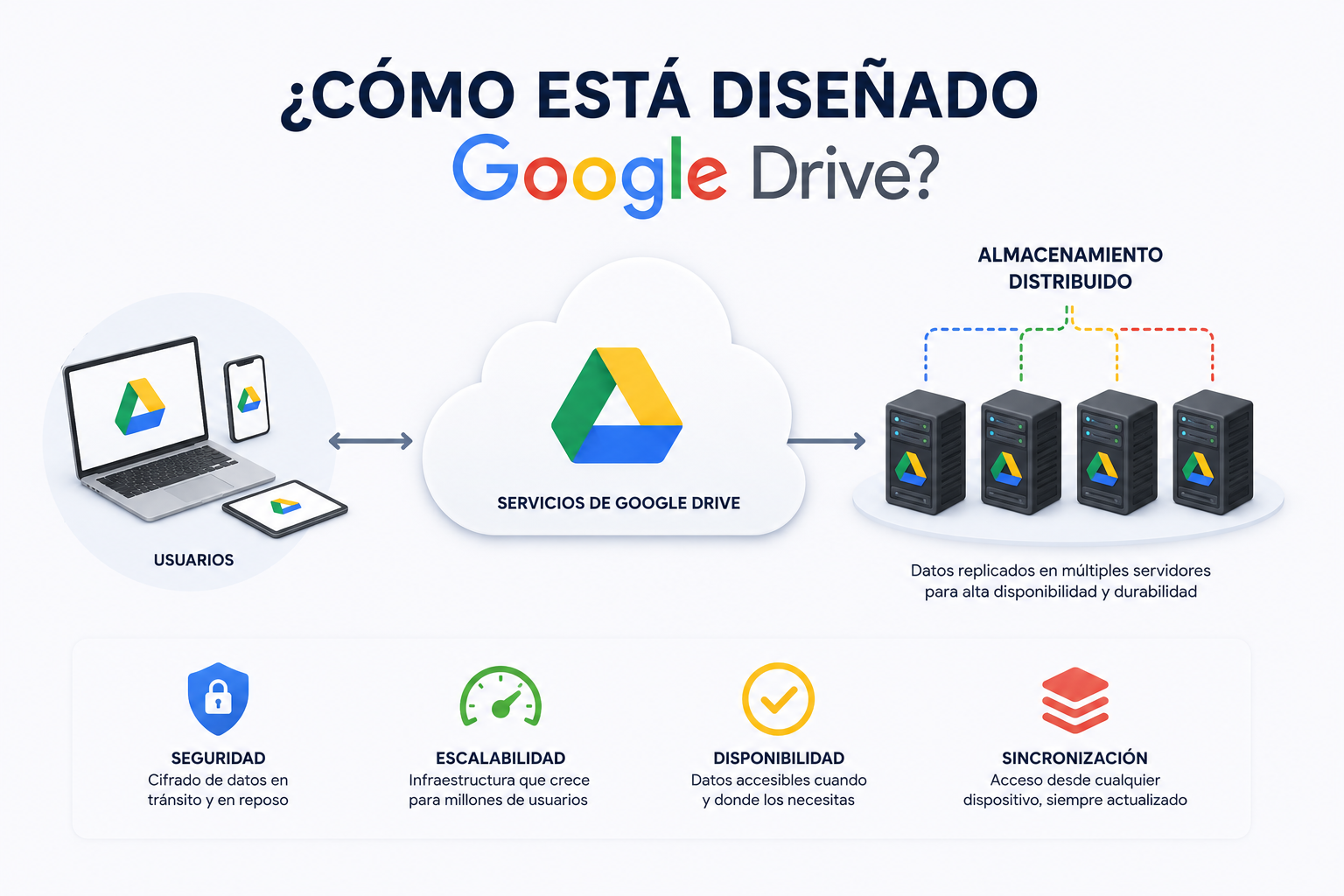
Google Drive almacena más de 2 billones de archivos y es utilizado por cientos de millones de personas en todo el mundo. Detrás de esa interfaz sencilla se esconde una de las arquitecturas distribuidas más sofisticadas que existen. En este artículo analizamos, capa por capa, cómo Google diseñó un sistema capaz de ofrecer almacenamiento masivo, sincronización instantánea y disponibilidad del 99.9 %.
Visión general de la arquitectura
Google Drive no es un servicio monolítico: es el resultado de componer múltiples sistemas internos de Google, cada uno especializado en resolver un problema concreto a escala planetaria.
- Colossus — sistema de archivos distribuido de nueva generación (sucesor de GFS) que almacena los bytes reales de los archivos.
- Bigtable / Spanner — bases de datos distribuidas que guardan todos los metadatos: quién posee qué, permisos, versiones, historial.
- Stubby / gRPC — protocolo RPC interno para la comunicación entre microservicios con latencia de microsegundos.
- Chubby — servicio de bloqueo distribuido utilizado para coordinar procesos de liderazgo y configuración crítica.
- Google Front End (GFE) — capa de ingreso global que enruta peticiones al datacenter más cercano y termina TLS.
Cada capa resuelve un problema diferente. Juntas forman un sistema que, desde el exterior, parece simplemente una carpeta en la nube.
Almacenamiento de archivos: Colossus y la fragmentación en chunks
Cuando subes un archivo a Google Drive, no se guarda como un bloque único. Colossus lo divide en fragmentos (chunks) de 64 MB y los distribuye por múltiples nodos de almacenamiento en distintos racks y zonas.
¿Por qué fragmentar en 64 MB?
El tamaño de chunk balancea dos fuerzas opuestas: fragmentos demasiado pequeños generan demasiados metadatos; fragmentos demasiado grandes dificultan la recuperación ante fallos y la distribución de carga. 64 MB es el punto óptimo para los patrones de acceso de Google.
Replicación y códigos de borrado
Para archivos frecuentemente accedidos, Colossus mantiene 3 réplicas en zonas diferentes. Para archivos fríos (sin acceso reciente), reemplaza la replicación por códigos de borrado Reed-Solomon, que ofrecen la misma tolerancia a fallos con un 50 % menos de overhead de almacenamiento.
# Analogía simplificada: cómo Reed-Solomon codifica datos
# Se generan 'k' fragmentos de datos + 'm' fragmentos de paridad
# Con k=6, m=3: se pueden perder hasta 3 fragmentos sin perder datos
fragmentos_datos = 6
fragmentos_paridad = 3
total_fragmentos = 9 # solo 1.5x overhead vs 3x de replicación triple
Metadatos: Spanner y la consistencia global
Los bytes de un archivo viven en Colossus, pero todo lo demás —nombre, propietario, permisos, versiones, árbol de carpetas— vive en Cloud Spanner, la base de datos relacionalmente consistente y distribuida globalmente de Google.
¿Por qué Spanner y no una BD tradicional?
Spanner combina las garantías ACID de una base de datos relacional con la escalabilidad horizontal de NoSQL. Usa el protocolo Paxos para lograr consenso entre réplicas en distintos continentes, y su característica más famosa —TrueTime— asigna marcas de tiempo absolutas con un margen de error de solo ±7 ms usando relojes atómicos y GPS en cada datacenter.
-- Ejemplo conceptual: tabla de metadatos de archivos en Spanner
CREATE TABLE drive_files (
file_id STRING(36) NOT NULL,
owner_user_id STRING(36) NOT NULL,
name STRING(255),
parent_id STRING(36),
size_bytes INT64,
mime_type STRING(128),
created_at TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true),
updated_at TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true),
trashed BOOL DEFAULT (FALSE),
) PRIMARY KEY (owner_user_id, file_id);
La clave primaria compuesta por owner_user_id + file_id garantiza que todos los archivos de un usuario se almacenen en el mismo nodo Spanner, reduciendo la latencia de lectura del árbol de carpetas.
Sincronización en tiempo real: el protocolo de delta
Cuando editas un Documento de Google o mueves un archivo, los cambios deben propagarse a todos tus dispositivos en segundos. Google Drive usa un modelo push + pull basado en long polling y notificaciones por canales de push.
Flujo de sincronización
- El cliente registra un canal de notificación (webhook o long-poll) en la API de Drive para un recurso específico.
- Cuando el recurso cambia, el servidor envía una notificación mínima (resource ID + token de cambio) sin el payload completo.
- El cliente solicita los deltas incrementales desde su último pageToken conocido usando
changes.list. - Solo se transfieren los metadatos cambiados y, si el contenido cambió, únicamente los chunks modificados.
import googleapiclient.discovery
service = googleapiclient.discovery.build('drive', 'v3', credentials=creds)
# Obtener token de página inicial
response = service.changes().getStartPageToken().execute()
page_token = response.get('startPageToken')
# Consultar cambios desde ese token
while page_token:
result = service.changes().list(
pageToken=page_token,
spaces='drive',
includeRemoved=True
).execute()
for change in result.get('changes', []):
print(f"Cambio en: {change['fileId']} — {change.get('file', {}).get('name')}")
page_token = result.get('nextPageToken') # None si no hay más cambios
Control de acceso y compartición
Google Drive implementa un modelo de ACL (Access Control Lists) con tres niveles de herencia: archivo individual → carpeta → dominio. Internamente, cada permiso se almacena como una entrada en Spanner vinculada al file_id. Cuando Drive evalúa si un usuario puede acceder a un archivo, recorre el árbol de carpetas hacia arriba hasta encontrar una ACL aplicable o llegar a la raíz, un proceso optimizado con caché de permisos en memoria con TTL corto.
- Viewer: puede ver el archivo, sin editar ni compartir.
- Commenter: puede ver y agregar comentarios.
- Editor: puede ver, editar y compartir de forma limitada.
- Owner: control total, incluyendo transferencia de propiedad.
Los links de compartición usan un token opaco que se valida contra Spanner en cada petición, sin exponer el ID real del archivo ni los metadatos del propietario.
Alta disponibilidad y recuperación ante fallos
Google Drive promete un SLA del 99.9 % mensual (menos de 44 minutos de downtime al año). Esto se logra mediante múltiples estrategias:
Distribución multi-región
Los datos se replican automáticamente en al menos dos regiones geográficas. Si un datacenter completo queda fuera de línea, el tráfico se redirige en segundos al datacenter secundario sin pérdida de datos.
Degradación gradual y uploads reanudables
Si el servicio de metadatos tiene latencia alta, Drive puede servir la última versión conocida desde caché mientras el problema se resuelve. Para archivos grandes, Drive usa el protocolo de upload reanudable: el cliente obtiene primero una URL de sesión y sube el archivo en bloques de 256 KB a 100 MB. Si la conexión se corta, retoma desde el último byte confirmado.
import time, random
def upload_with_backoff(file_data, max_retries=5):
delay = 1 # segundo
for attempt in range(max_retries):
try:
return upload_chunk(file_data)
except TransientError:
if attempt == max_retries - 1:
raise
jitter = random.uniform(0, delay * 0.1)
time.sleep(delay + jitter)
delay = min(delay * 2, 32) # máximo 32 segundos
Rendimiento: CDN, caché y compresión
La latencia es crítica para la experiencia de usuario. Google aplica varias técnicas en paralelo:
- Edge caching (CDN): los archivos públicos o frecuentemente accedidos se sirven desde nodos de borde geográficamente cercanos al usuario.
- Compresión Brotli: documentos de texto y JSON se comprimen antes de la transferencia, reduciendo el tamaño hasta un 20 % más que gzip.
- HTTP/2 y QUIC: multiplexación de streams y eliminación de head-of-line blocking. Google Drive migró a QUIC (UDP) para mejorar el rendimiento en redes con pérdida de paquetes.
- Prefetching inteligente: el cliente de Drive predice qué archivos vas a necesitar (basándose en patrones de apertura) y los descarga en segundo plano.
Lecciones de diseño aplicables a cualquier sistema
El diseño de Google Drive encierra principios universales que puedes aplicar en tus propios proyectos:
- Separa metadatos de datos. Guarda los bytes en un almacenamiento optimizado para blobs y los metadatos en una BD indexada. Nunca mezcles ambos en la misma tabla.
- Diseña para fallos parciales. Cualquier componente puede fallar. Usa reintentos con backoff, circuit breakers y degradación gradual en lugar de asumir éxito.
- Prefiere deltas sobre snapshots. Enviar solo lo que cambió es siempre más eficiente que retransmitir el estado completo, especialmente a escala.
- La consistencia tiene un costo. Elige el nivel de consistencia que tu aplicación realmente necesita. Drive acepta consistencia eventual para lecturas de directorio, pero exige consistencia fuerte para permisos.
- Haz los uploads reanudables desde el inicio. Retrofittear el soporte de reanudación en un sistema existente es doloroso; diseñarlo desde el principio es barato.
Conclusión
Google Drive es mucho más que una carpeta en la nube. Es la convergencia de Colossus para el almacenamiento masivo, Spanner para los metadatos globalmente consistentes, protocolos de delta para la sincronización eficiente y una arquitectura multi-región para la alta disponibilidad. Comprender cómo funciona internamente no solo satisface la curiosidad técnica: te da un mapa mental para diseñar tus propios sistemas de almacenamiento, sincronización y distribución de datos a cualquier escala.